0 Introduction
High-quality data is the foundation of modern deep learning systems and improving annotation efficiency has become a key engineering challenge. Recent advances in foundation models, such as the Segment Anything Model (SAM) family, offer a promising direction to address this problem. By leveraging strong generalization and promptable segmentation capabilities, these models can significantly reduce manual annotation effort and enable scalable semi-automatic labeling workflows. This blog focuses on how SAM3 can be used to accelerate data annotation from multiple perspectives:
- Section 1: provides a brief introduction to SAM3, highlighting its core capabilities and improvements over previous SAM versions.
- Section 2: demonstrates how SAM3 can be integrated into an annotation platform to support fast, semi-automatic annotation, reducing human effort while maintaining control and accuracy.
- Section 3: discusses how fine-tuning SAM3 on a target dataset can further improve segmentation quality, making it more suitable for domain-specific annotation tasks.
- Section 4: explores how SAM3 can speed up annotation workflows beyond standard image segmentation, enabling efficient labeling for other downstream tasks.
1 What is SAM
Segment Anything Model (SAM) is a foundation model for image segmentation introduced by Meta AI. The core idea is to create a promptable, general-purpose segmentation model that can segment any object in an image without task-specific training. The table below shows the comparison of the three versions of SAM, the fundmental improvement of SAM3 is now it support language prompt for segmentation compared to previous versions SAM 2.
| Feature Aspect | SAM1 | SAM2 | SAM3 |
|---|---|---|---|
| Major New Capability | Zero-shot promptable image segmentation using visual prompts (points, boxes, masks). | Adds video segmentation and object tracking via streaming memory. | Adds Promptable Concept Segmentation: open-vocabulary text prompts and exemplar-based segmentation. |
| Training Dataset | SA-1B: ~11M images | SA-1B + SA-V (50.9K video) + Internal (62.9K video) | SA-1B + SA-V + SA-Co (~5.2M images/52.5K videos, >4M unique concept phrases) |
| Prompt Types | Points, boxes, masks | Points, boxes, masks | Text, points, boxes, masks |
| Supported Media | Images only | Images and videos | Images and videos |
The SAM 3 architecture builds primarily upon two distinct predecessors: SAM 2 and the Perception Encoder.
The overall architecture of SAM 3 is designed as a unified framework for both image and video segmentation. It utilizes a shared image encoder to process visual data, which then feeds into specialized components for detection and tracking. As illustrated in the figure below, the architecture consists of a dual encoder-decoder transformer—combining a detector for image-level capabilities with a tracker and memory module for video. Both the detector and tracker ingest vision-language inputs from an aligned Perception Encoder (PE) backbone.
Beyond the foundational architecture, two key mechanisms drive the model’s performance:
Leveraging Language Prompts for Segmentation
SAM 3 integrates text prompts to guide segmentation, a feature central to its “Promptable Concept Segmentation” (PCS) capability. The process begins with a text encoder that converts the prompt into a text embedding. These embeddings are then cross-referenced with image features generated by the shared image encoder. This mechanism effectively “conditions” the model, highlighting visual regions that semantically align with the text prompt.
The Memory Bank for Video Segmentation
For video tasks, SAM 3 advances tracking by fusing a stateless concept detector with SAM 2’s stateful memory tracker. Unlike simple motion trackers, SAM 3 relies on a dedicated Memory Bank that stores feature embeddings from previous frames. For each new frame, the model employs cross-attention to “look back” at this memory. By recalling the object’s specific appearance and history, SAM 3 can accurately predict the new shape (masklet) of the target, maintaining robust tracking even if the object rotates, changes pose, or undergoes occlusion.
2 Integrate SAM3 with Label Studio
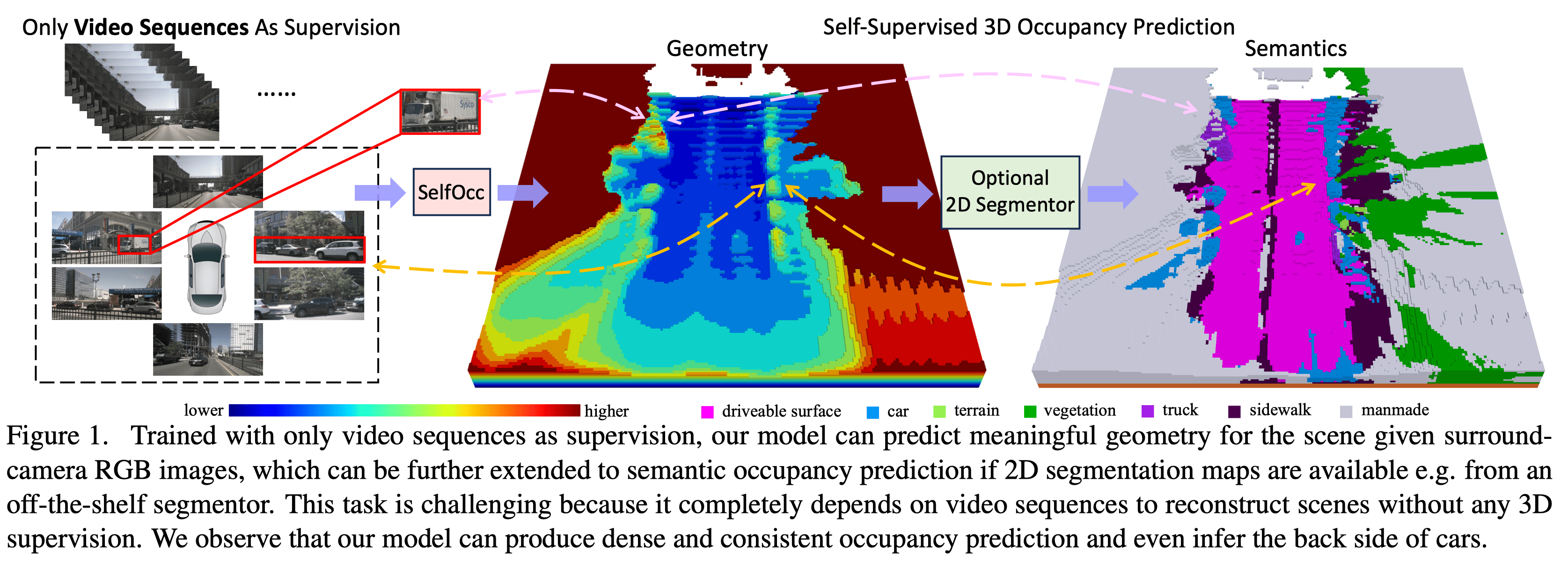
The installation of SAM 3 is very straightforward, you can follow the instruction in the github to install it. Label Studio provide a web interface for annotation and a standardized ML backend to use the model to handle the interactive request . We can easily integrate SAM 3 with Label Studio by using the Label Studio API. Here are the examples of using SAM 3 with Label Studio. Let’s use burger 🍔 as an example to illustrate how SAM 3 can boost our annotation efficiency.
Box prompt
You can see there are two burgers in the image. When we use a bounding box to select just the left burger, SAM 3 automatically segments both burgers and stores them as two separate masks. This demonstrates that SAM 3 can be used for instance segmentation and can identify similar objects beyond the one explicitly selected.
“Box prompt in label studio(click to play)”
Text prompt
It can not only respond to the instance name we can also add some object description to the text prompt to segment the specific object.
We enter the text prompt “burger in the middle”. The model will only segment the burger in the middle of the image and ignore the other two burgers.
“Text prompt in label studio(click to play)”
Point prompt When given a point prompt, the model segments the object underneath that point. It may return multiple masks due to ambiguity regarding segmentation granularity. For example, a selected point on a burger could indicate that the user wants to segment only the top bun(bread) or the whole burger.
“Point prompt in label studio(click to play)”
3 Model Finetuning
Despite the remarkable generalist capabilities of SAM—derived from its training on the SA-1B dataset comprising over 1.1 billion masks, we can still easily encounter scenarios where it fails or performs poorly. To fix this, we need to adapt the model and finetune the model for target datasets. The literature categorizes these finetuning strategies in two ways: by how the user interacts with the model (Prompt Interaction) and by how we modify the weights (Parameter Strategy).
3.1 Prompt Interaction
First, we must decide whether to preserve SAM3’s promptable capability. Should it remain a generic segmentation model that responds to user prompts, or should we adapt it into an automated model that detects target objects on its own?
Closed-Set Segmentation Fine-Tuning
In many real-world scenarios, it is not realistic to manually click on every object. What we want instead is full automation. In this setting, SAM is fine-tuned to behave like a traditional segmentation network. The model is trained to detect a fixed set of predefined classes, such as surface defects in industrial inspection or certain land types in remote sensing, without any user prompts.
By removing the dependence on points or bounding boxes, the model can automatically locate and segment targets directly from the image. However, this comes with a clear trade-off. The model no longer keeps its open-world ability. It is no longer a true “segment anything” model, but rather a task-specific tool that only segments the categories it was trained on.
Interactive and Prompt-Preserving Fine-Tuning
One risk of fine-tuning SAM is that the model may gradually “forget” how to follow user prompts. If the training only uses image–mask pairs, the model often overfits to the visual patterns of the target objects and starts to ignore the prompt encoder. In practice, it learns to rely only on appearance and may no longer respond properly to clicks or boxes.
To avoid this problem and keep human interaction effective, we adopt a method known as Prompt Simulation Training. This approach follows the original training strategy of SAM. During training, synthetic prompts are generated automatically, such as bounding boxes with small random offsets or jitter around the target objects. By doing this, the model is forced to pay attention to the spatial information provided by the prompts. As a result, SAM remains responsive to user prompts.
3.2 Parameter Strategy
When we consider updating the model’s weights, the most obvious idea is to retrain the entire network. However, in practice this is rarely adopted. Methods that freeze key components are not simply cutting corners to reduce computation; instead, they serve to intentionally anchor the model. By fixing the pre-trained backbone, we can ensure that the network preserves and makes use of the rich, general representations learned from training on 1.1 billion masks. Rather than overwriting this strong foundation, the model is encouraged to build on top of it, treating SAM’s original knowledge as a stable base and only learning the necessary adaptations for the new domain. Because of this, the industry standard has shifted entirely to Parameter-Efficient Finetuning (PEFT).
Decoder-Only Tuning (The “Lightweight” Approach)
The most straightforward method, notably employed in the early stages of MedSAM, involves freezing the massive Image Encoder and updating only the weights of the lightweight Mask Decoder. This approach is attractive because it is computationally efficient; since the heavy encoder is frozen, image embeddings can be pre-calculated and cached, which drastically speeds up the training process. However, this efficiency comes at a cost. The frozen encoder creates a hard information bottleneck. If the base ViT fails to “see” a subtle feature—such as a low-contrast tumor indistinguishable from surrounding tissue—the decoder simply lacks the information required to generate an accurate mask, regardless of how much it is fine-tuned.
Adapter Methods
To address the limitations of a frozen encoder, Adapter methods introduce new architectural blocks inserted sequentially or in parallel within the transformer layers. Unlike the decoder-only approach, adapters allow the model to learn new feature extraction capabilities without modifying the original pre-trained weights. This is particularly useful for injecting “priors,” such as feeding high-frequency edge maps into the network to help the model detect camouflaged objects, as seen in the SAM-Adapter framework. The primary disadvantage of this strategy is the “latency tax.” Because adapters add physical layers to the network depth that cannot be mathematically merged, they impose a permanent computational penalty during inference, making them less ideal for real-time applications.

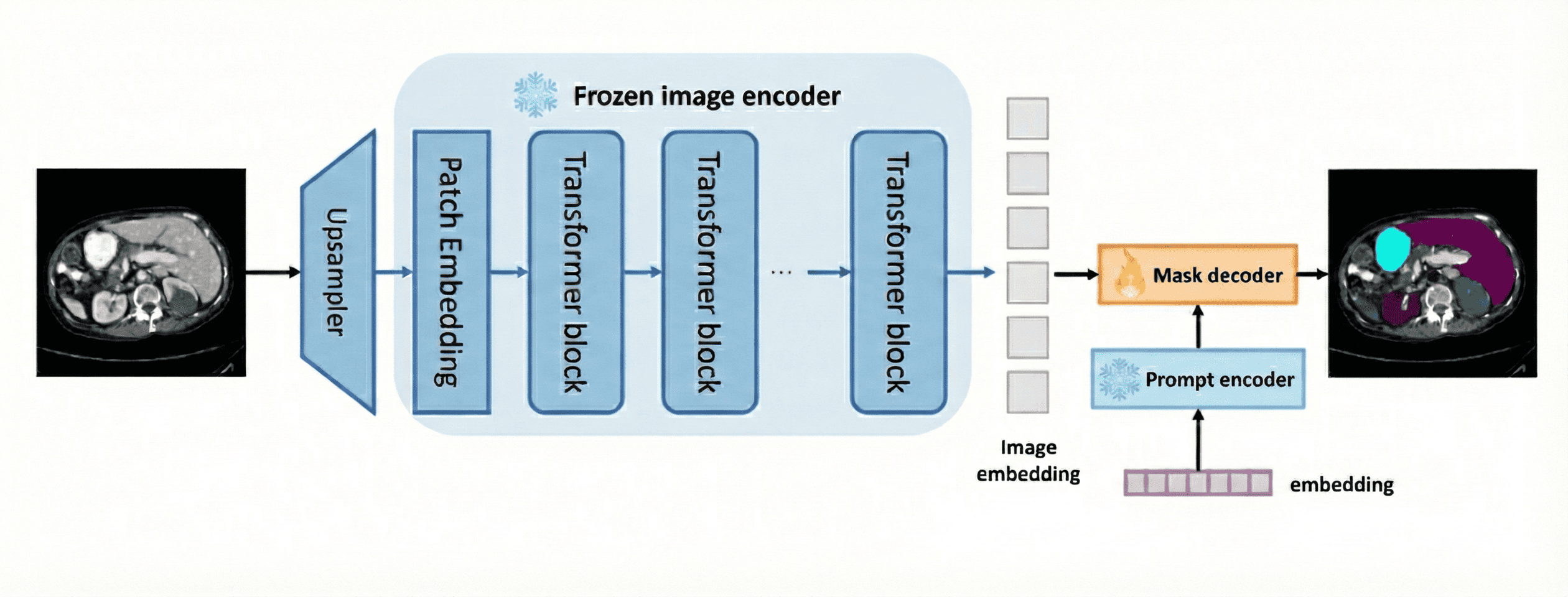
LoRA based method
LoRA has become the industry standard for adapting foundation models because it successfully balances performance with efficiency. Instead of retraining the full model or adding heavy adapter layers, LoRA operates on the premise that weight updates have a low intrinsic rank. It injects small, trainable low-rank matrices into the attention layers (typically the Query, Key, and Value projections) of the encoder. Mathematically, instead of updating a massive weight matrix $W$, LoRA learns two tiny matrices $A$ and $B$ such that the update becomes $W + BA$. This formulation offers a distinct “Zero Latency” advantage over standard adapters. After training, these $BA$ matrices can be mathematically merged back into the original model weights ($W_{final} = W + BA$). This means the fine-tuned model runs at the exact same inference speed as the original SAM, with zero additional latency, a technique central to efficient models like SAM2LoRA.
3.3 Simple example of finetuning
We use the code from SAMed to finetune the SAM model. The example is shown below. After finetuning, the model can segment the “chicken” much better than the original model.

4 Speed up annotation workflows beyond standard image segmentation
Image segmentation is a fundamental task in computer vision, and it elevates many downstream tasks. SAM3 is a general-purpose segmentation model, it can be used for various tasks or assisting generate training data for other tasks. Due to limited page space, we will only introduce the following three applications in this post with some examples, may not include all the algorithmic details. We will probably add more details in separate posts..
4.1 Video and Image Editing Pipelines
The SAM series has become a foundational tool in the image and video generation community due to its strong promptable segmentation capability and generalization across domains. SAM 3 further extends this to temporal-consistent video segmentation, enabling users to interactively select, track, and manipulate objects across frames with minimal manual effort. In practical workflows, SAM-based models are already integrated into popular visual generation platforms such as ComfyUI, where segmentation masks serve as first-class citizens. These masks are widely used for:
- Object-level editing (background replacement, object removal, inpainting, style transfer)
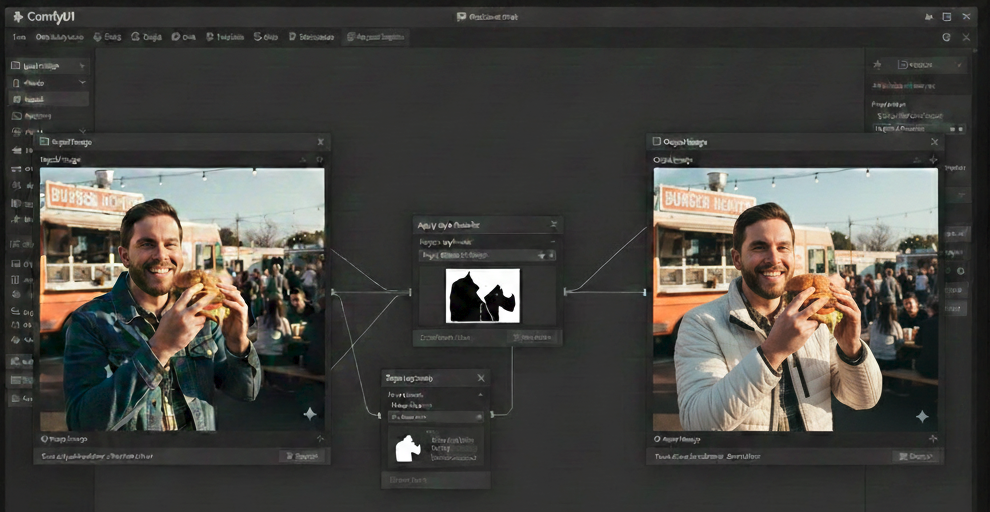
- Motion-aware video editing by propagating masks across time By reducing the need for frame-by-frame annotation and offering robust object tracking, SAM 3 significantly lowers the barrier for high-quality video editing and content creation, making it a key infrastructure model in modern creative pipelines. The figure illustrates an example of using SAM 3 for image editing within ComfyUI. By providing a segmentation mask of the jacket as a visual prompt, the image generation model can selectively modify the clothing while preserving the rest of the scene, enabling precise and controllable edits.
4.2 Data Provider for Vision-Language Large Models (VLLMs)
Most existing Vision-Language Large Models (VLLMs) focus on image-level or region-level understanding, and typically lack native support for pixel-level reasoning. This limits their ability to perform fine-grained tasks such as precise localization, dense reasoning, or object-part understanding. SAM 3 can act as a pixel-level perception frontend for VLLMs by converting raw visual inputs into structured segmentation representations. These representations can then be used to:
- Provide explicit object boundaries and instance identities
- Enable region-conditioned visual reasoning
- Support mask-based prompting for VLLMs
Recent works such as OMG-LLaVA demonstrate that incorporating segmentation-aware representations significantly improves VLLMs’ performance on dense prediction and reasoning tasks. In this context, SAM 3 serves as a scalable data engine, generating high-quality pixel-level annotations (instance masks, temporal tracks) that enrich VLLM training data and inference-time perception, bridging the gap between foundation vision models and language-driven reasoning.The figure below illustrates how pixel-level segmentation enables fine-grained vision-language interaction, including grounded descriptions, referring expressions, and region-conditioned reasoning. By explicitly linking language to object masks and spatial regions, models can move beyond image-level understanding to precise localization and compositional reasoning.

4.3 Supporting 3D Perception and Autonomous Systems
Cameras provide richer semantic and appearance details compared to LiDAR or radar, which are inherently sparse and geometry-centric. Consequently, in robotics and autonomous driving, high-fidelity image and video segmentation has become a foundational tool for 3D perception annotation in the following ways:
3D annotation generation: Projecting 2D segmentation masks into 3D space to assist in labeling 3D occupancy, object detection.
Annotation verification and refinement: Using high-quality 2D masks as a semantic reference to validate or correct noisy 3D annotations.